In the era of information explosion, we navigate through vast amounts of data every day, trying to find truly valuable information. The emergence of the Retrieval Augmented Generation (RAG) system is like a beacon, illuminating our path forward in the ocean of information. But have you ever thought about why the RAG system can accurately provide us with useful information? Behind it, there is actually a key “gatekeeper” — the reranker. Today, let’s explore the world of rerankers together and see how they play an indispensable role in the RAG system.
I. What is a reranker in RAG?
Imagine this: when you input a keyword into a search engine, the system instantly retrieves thousands of related pieces of information from a massive database. However, the quality of this information varies, with some being highly relevant to your needs and others being completely irrelevant. This is where the reranker comes in.
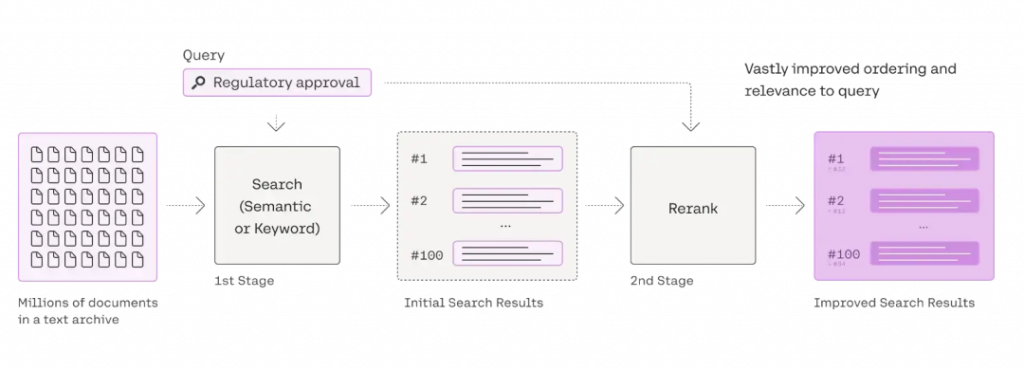
The reranker is like a strict quality inspector. It performs a second screening and sorting of the initially retrieved documents. In the initial retrieval phase, the system may use semantic search or keyword search methods to quickly find a batch of documents that are somewhat related to the query content. But these documents are like unfiltered raw materials, potentially containing much irrelevant information. The task of the reranker is to select the parts most relevant to the user’s query intent from these documents, placing them at the forefront, thereby improving the quality of the search results.
For example, suppose you are writing a paper on “the application of artificial intelligence in the medical field,” and you retrieve related materials through the RAG system. The initial retrieval might give you dozens of papers, news reports, and research reports covering various aspects of AI’s applications in medical imaging diagnosis, disease prediction, drug development, etc. But some content may only briefly mention artificial intelligence and medicine without delving into their relationship. The reranker will carefully analyze these documents, placing those that thoroughly describe specific application cases, technical principles, and effectiveness evaluations of AI in the medical field at the front, allowing you to quickly find the most helpful information.
II. Why use a reranker in RAG?
1. Reducing “Hallucination” Phenomenon
In the RAG system, there is a common problem called “hallucination.” Simply put, the system generates responses that are inconsistent with facts or meaningless. This usually occurs because the retrieved documents contain a large amount of irrelevant information, misleading the system when generating responses. The reranker can effectively filter out these irrelevant documents, akin to picking out bad parts from ingredients, thereby reducing the occurrence of “hallucination.”
2. Cost Savings
You might think that since the RAG system retrieves documents so quickly, retrieving more documents isn’t a big deal. In reality, processing these documents consumes a lot of computational resources and API call fees. If the reranker can precisely screen out the most relevant documents, it reduces the amount of information the system needs to process, thus saving costs. This is similar to shopping: if you can accurately find the products you want, you don’t need to waste time and energy browsing through numerous unrelated items, also reducing shopping costs.
3. Overcoming Limitations of Embedding Vectors
In the RAG system, embedding vectors are a commonly used method for information representation. They map documents and query content into a low-dimensional vector space and determine relevance by calculating the similarity between vectors. However, this method has certain limitations. First, embedding vectors may not accurately capture subtle semantic differences. For instance, “I like eating apples” and “I like eating apple pie” are semantically related but clearly distinct; embedding vectors may fail to distinguish them well. Second, compressing complex information into a low-dimensional space may lead to information loss. Finally, embedding vectors may exhibit insufficient generalization ability when handling information beyond their training data range. The reranker can address these shortcomings by using more complex matching techniques to conduct a finer analysis and ranking of documents.
III. Advantages of Rerankers
1. “Bag-of-Words Embedding” Method
Unlike embedding vectors, which map an entire document to a single vector, the reranker breaks down the document into smaller units with contextual information, such as sentences or phrases. This allows it to understand the semantics of the document more accurately. Just like reading an article, we don’t conclude based solely on the title; instead, we read each paragraph and sentence carefully to better understand the main idea.
2. Semantic Keyword Matching
The reranker combines powerful encoder models (like BERT) with keyword-based technologies, capturing both the semantic meaning of the document and the relevance of keywords. This is akin to looking for a book: we not only look at the title and synopsis but also check the keyword index to more accurately judge whether the book meets our needs.
3. Better Generalization Ability
Because the reranker focuses on small units within the document and contextual information, it performs exceptionally well when dealing with unseen documents and queries. This is like an experienced detective who can infer the truth of a case based on subtle clues on the scene, even if he has never encountered a similar case before.
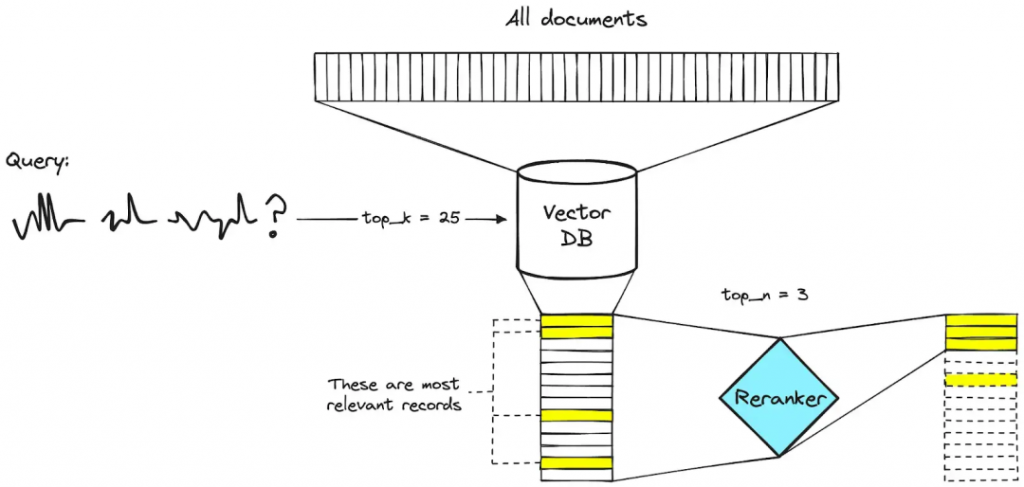
IV. Types of Rerankers
The world of rerankers is rich and colorful, with new technologies and methods constantly emerging. Let’s take a look at several common types of rerankers.
1. Cross-Encoder
A cross-encoder is a deep learning model that classifies and analyzes pairs of queries and documents, deeply understanding their relationships. It’s like a professional translator who not only understands the literal meanings of two languages but also accurately grasps their semantic connections. Cross-encoders excel in precise relevance scoring but require substantial computational resources, making them less suitable for real-time applications.
Example: Suppose we use FlashrankRerank as the reranker combined with ContextualCompressionRetriever to improve the relevance of retrieved documents. The code is as follows:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import FlashrankRerank
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
compressor = FlashrankRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
print([doc.metadata["id"] for doc in compressed_docs])
pretty_print_docs(compressed_docs)This code uses FlashrankRerank to reorder the documents retrieved by the base retriever according to their relevance to the query “What did the president say about Ketanji Jackson Brown.” Ultimately, it prints out the IDs of the documents and the compressed, reordered document contents.
2. Multi-Vector Reranker
Multi-vector models like ColBERT adopt a delayed interaction approach. Queries and representations of documents are independently encoded, and their interaction occurs later in the processing. This method allows pre-computation of document representations, speeding up retrieval and reducing computational demands.
Example using ColBERT reranker:
pip install -U ragatouille
from ragatouille import RAGPretrainedModel
from langchain.retrievers import ContextualCompressionRetriever
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")
compression_retriever = ContextualCompressionRetriever(
base_compressor=RAG.as_langchain_document_compressor(), base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What animation studio did Miyazaki found"
)
print(compressed_docs[0])This code uses the ColBERT reranker to compress and reorder the retrieved documents to answer the question “Which animation studio did Miyazaki found?” The output contains information about Miyazaki founding Studio Ghibli, the studio’s background, and its first movie.
3. Fine-tuned Large Language Models (LLMs)
Fine-tuning LLMs is key to improving their performance in reranking tasks. Pre-trained LLMs themselves are not adept at measuring the relevance between queries and documents. By fine-tuning them on specific ranking datasets (like the MS MARCO passage ranking dataset), we can enhance their performance in document ranking. Depending on the model structure, supervised rerankers mainly fall into two categories:
- Encoder-decoder models: These models treat document ranking as a generative task, optimizing the reranking process using an encoder-decoder framework. For example, the RankT5 model is trained to generate labels to classify query-document pairs as relevant or irrelevant.
- Decoder-only models: This approach focuses on fine-tuning decoder-only models like LLaMA. Models like RankZephyr and RankGPT explore different ways of calculating relevance in this context.
Applying these fine-tuning techniques improves the performance of LLMs in reranking tasks, making them more effective in understanding and prioritizing relevant documents.
Example using RankZephyr:
pip install --upgrade --quiet rank_llm
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_community.document_compressors.rankllm_rerank import RankLLMRerank
compressor = RankLLMRerank(top_n=3, model="zephyr")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(query)
pretty_print_docs(compressed_docs)This code uses RankZephyr to reorder the retrieved documents, selecting the top 3 most relevant documents based on the query. The output includes various pieces of information related to the query, such as economic sanctions against Russia, closing U.S. airspace to Russian flights, etc.
4. Using LLMs as “Judges” for Reranking
Large language models can autonomously improve document reranking through prompting strategies (such as pointwise, listwise, and pairwise approaches). These methods leverage the reasoning capabilities of LLMs (using them as “judges”) to directly assess the relevance of documents to queries. Although these methods are competitive in terms of effectiveness, high computational costs and delays associated with LLMs may hinder practical applications.
- Pointwise Approach: Pointwise methods evaluate the relevance of a single document to a query. It includes two subcategories: relevance generation and query generation. Both methods are suitable for zero-shot document reranking, i.e., ranking documents without prior training on specific examples.
- Listwise Approach: Listwise methods rank a list of documents by including the query and the document list in the prompt. The LLM is then instructed to output identifiers for the reranked documents. Due to the limited input length of LLMs, it is often impossible to include all candidate documents at once. To manage this situation, listwise methods employ a sliding window strategy, ranking one subset of documents at a time, moving the window backward, and only reranking documents within the current window.
- Pairwise Approach: In the pairwise approach, the LLM receives a prompt containing the query and a pair of documents. The model’s task is to determine which document is more relevant. Methods like AllPairs can aggregate results by generating all possible document pairs and calculating final relevance scores for each document. Efficient sorting algorithms like heap sort and bubble sort help speed up the ranking process.
Example using OpenAI’s GPT-4-turbo model for pointwise, listwise, and pairwise reranking:
import openai
# Set your OpenAI API key
openai.api_key = 'YOUR_API_KEY'
def pointwise_rerank(query, document):
prompt = f"Rate the relevance of the following document to the query on a scale from 1 to 10:
Query: {query}
Document: {document}
Relevance Score:"
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}]
)
return response['choices'][0]['message']['content'].strip()
def listwise_rerank(query, documents):
# Use a sliding window approach to rerank documents
window_size = 5
reranked_docs = []
for i in range(0, len(documents), window_size):
window = documents[i:i + window_size]
prompt = f"Given the query, please rank the following documents:
Query: {query}
Documents: {', '.join(window)}
Ranked Document Identifiers:"
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}]
)
ranked_ids = response['choices'][0]['message']['content'].strip().split(', ')
reranked_docs.extend(ranked_ids)
return reranked_docs
def pairwise_rerank(query, documents):
scores = {}
for i in range(len(documents)):
for j in range(i + 1, len(documents)):
doc1 = documents[i]
doc2 = documents[j]
prompt = f"Which document is more relevant to the query?
Query: {query}
Document 1: {doc1}
Document 2: {doc2}
Answer with '1' for Document 1, '2' for Document 2:"
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}]
)
winner = response['choices'][0]['message']['content'].strip()
if winner == '1':
scores[doc1] = scores.get(doc1, 0) + 1
scores[doc2] = scores.get(doc2, 0)
elif winner == '2':
scores[doc2] = scores.get(doc2, 0) + 1
scores[doc1] = scores.get(doc1, 0)
# Sort documents based on scores
ranked_docs = sorted(scores.items(), key=lambda item: item[1], reverse=True)
return [doc for doc, score in ranked_docs]
# Example usage
query = "What are the benefits of using LLMs for document reranking?"
documents = [
"LLMs can process large amounts of text quickly.",
"They require extensive fine-tuning for specific tasks.",
"LLMs can generate human-like text responses.",
"They are limited by their training data and may produce biased results."
]
# Pointwise Reranking
for doc in documents:
score = pointwise_rerank(query, doc)
print(f"Document: {doc} - Relevance Score: {score}")
# Listwise Reranking
reranked_listwise = listwise_rerank(query, documents)
print(f"Listwise Reranked Documents: {reranked_listwise}")
# Pairwise Reranking
reranked_pairwise = pairwise_rerank(query, documents)
print(f"Pairwise Reranked Documents: {reranked_pairwise}")This code uses pointwise, listwise, and pairwise methods to reorder a set of documents. The output shows the relevance scores of each document and the order after reordering via different methods.
5. Reranking APIs
Private reranking APIs provide organizations with a convenient solution to enhance the semantic relevance of their search systems without significant infrastructure investment. Companies like Cohere, Jina, and Mixedbread offer these services.
- Cohere: Offers custom models for English and multilingual documents, automatically chunks documents, and normalizes relevance scores between 0 and 1.
- Jina: Focuses on enhancing search results through semantic understanding and provides longer context lengths.
- Mixedbread: Offers a range of open-source reranking models, providing flexibility for integration into existing search infrastructures.
Example using Cohere:
pip install --upgrade --quiet cohere
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
from langchain.chains import RetrievalQA
llm = Cohere(temperature=0)
compressor = CohereRerank(model="rerank-english-v3.0")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
chain = RetrievalQA.from_chain_type(
llm=Cohere(temperature=0), retriever=compression_retriever
)This code uses Cohere’s reranking model to reorder the retrieved documents to answer a query about Ketanji Brown Jackson. The output contains the president’s high praise for Ketanji Brown Jackson and her support.
V. How to Choose the Right Reranker for RAG?
Choosing the most suitable reranker for the RAG system requires considering multiple factors comprehensively:
1. Relevance Improvement
The primary goal of the reranker is to improve the relevance of search results. Metrics such as Normalized Discounted Cumulative Gain (NDCG) or attribution can be used to evaluate the reranker’s effect on relevance improvement. Just as evaluating a chef’s skills involves seeing if the dishes meet guests’ tastes, we must see if the reranker can truly enhance the quality of search results.
2. Latency
Latency refers to the additional time the reranker adds to the search process. Ensure this time is within the acceptable range required by your application. If a reranker, although improving relevance, takes too long, it may not be suitable for scenarios requiring high real-time performance. In a tense competition, you need to make correct decisions quickly; if a tool takes too long to provide assistance, it may not be the best choice.
3. Context Understanding Ability
Consider the reranker’s ability to handle contexts of different lengths. In complex queries, longer context information may need to be considered, and some rerankers may perform better in this aspect. This is like reading an article: some readers can better understand long, difficult sentences and complex contextual relationships, while others may only grasp simple sentences.
4. Generalization Ability
Ensure the reranker performs well across different domains and datasets, avoiding overfitting. If a reranker performs well only in specific domains or datasets but poorly in other situations, it may not be reliable. This is like a student who excels in one subject exam but performs poorly in other subjects, indicating he may not be a well-rounded student.
VI. Latest Research Progress
1. Cross-Encoders Emerge
Recent studies show that cross-encoders, when used in conjunction with powerful retrievers, demonstrate efficiency and effectiveness. While the performance difference within domains may not be significant, the impact of rerankers is more pronounced in out-of-domain scenarios. Cross-encoders typically outperform most LLMs (except GPT-4 in some cases) in reranking tasks and are more efficient.
VII. Conclusion
Choosing the right RAG reranker is crucial for improving system performance and ensuring accurate search results. As the RAG field evolves, having a clear understanding of the entire process is vital for teams building effective systems. By addressing challenges in the process, teams can enhance performance. Understanding the different types of rerankers and their pros and cons is essential. Carefully selecting and evaluating RAG rerankers can enhance the accuracy and efficiency of RAG applications. This thoughtful approach will yield better results and more reliable systems.
In the RAG world, the reranker is like an unsung hero. Although it doesn’t interact directly with users, it silently provides precise and efficient information services. Hopefully, through a deeper understanding of rerankers, we can better utilize the RAG system, navigating the ocean of information smoothly and finding truly valuable knowledge treasures.
That concludes the detailed introduction to rerankers in the RAG system! If you’re interested in this topic or encounter related issues in practical applications, feel free to leave comments and discuss in the comment section! Let’s explore more mysteries of the RAG system together and progress collectively!
Reproduction without permission is prohibited:AI LAB » The Unsung Hero in RAG Systems: How Re-Rankers Enhance Information Retrieval Precision?